Cliff Walking: Sarsa vs. Q-Learning in Python
This article trains an agent in Python to move from the start to the goal without falling off the cliff. It implements and compares the Sarsa and Q-learning algorithms in reinforcement learning, and discusses the factors that shape the final solution.
1 | import numpy as np |
1 | def take_action(s,a): |
ε-Greedy
$$ \pi(a \mid s)\left\{\begin{array}{ll} \epsilon / m+1-\epsilon & \text { if } & a^{*}=\arg \max _{a \in A} Q(s, a) \\ \epsilon / m & \text { otherwise } \end{array}\right. $$
In code, we can first check whether \(X<1-\epsilon, X \sim \mu(0,1)\). If so, return the optimal action directly; otherwise, choose uniformly at random. This is equivalent to the formula above, but more convenient to implement.
1 | def epsilon_greedy(s,epsilon=0.1): |
Sarsa
$$ Q(S,A) \leftarrow Q(S,A)+\alpha (R+ \gamma Q(S',A')-Q(S,A)) $$
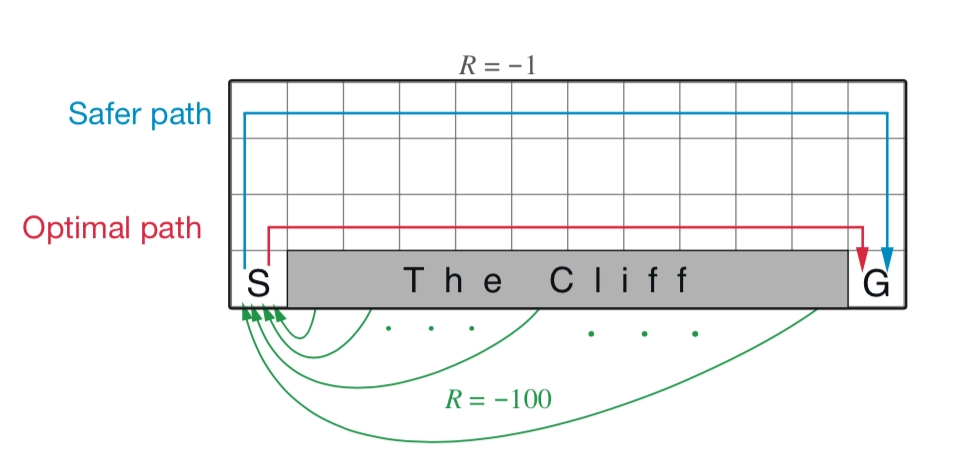
Sarsa is an on-policy algorithm. It optimizes the policy it actually executes, using the action it is going to take next to update the Q-table directly. During learning, there is only one policy: the same policy is used both to select actions and to optimize the table. Because of this, Sarsa knows that its next action may move toward the cliff, so when it optimizes its policy it tends to stay farther away from the cliff edge. That way, even if the next move contains randomness, it is still likely to remain in a safe area.
1 | def Sarsa(n=10000,alpha=0.01): |
Q-learning
$$ Q(S,A) \leftarrow Q(S,A)+\alpha (R+ \gamma \max_a Q(S',A')-Q(S,A)) $$
Q-learning is an off-policy algorithm. As shown in Figure 3.31, off-policy learning involves two different policies during training: the target policy and the behavior policy.
The target policy, usually denoted by \(\pi\), is the policy we want to learn. It is like a strategist directing tactics from the rear: it can learn the optimal policy from experience without interacting with the environment directly.
The behavior policy, usually denoted by \(\mu\), is the policy used to explore the environment. It can boldly explore all possible trajectories and collect data, then “feed” that data to the target policy for learning. Moreover, the data fed to the target policy does not need to include \(a_{t+1}\), whereas Sarsa does require \(a_{t+1}\). The behavior policy is like a soldier exploring all actions, trajectories, and experiences in the environment, then handing those experiences over to the target policy. When the target policy is updated, Q-learning does not care where exploration goes next; it simply selects the action with the largest reward.
1 | def Q_learning(n=10000,alpha=0.01): |
Discussion of the Results
Both Sarsa and Q-learning can converge to a path from the start to the goal. But clearly, Sarsa cannot always produce the globally optimal solution, and the larger ε is, the worse the convergence result becomes. This is because Sarsa uses ε-greedy to decide the next action after reaching \(S’\), so nodes near the cliff can easily fall off, which causes the target value function to be underestimated. In Q-learning, by contrast, the Q-value is always updated using the optimal action at the next state, so this problem does not arise.
Sarsa is a typical on-policy algorithm: it uses only one policy, \(\pi\). It uses policy \(\pi\) both to learn and to interact with the environment and generate experience. If the policy adopts an \(\varepsilon\)-greedy strategy, it must balance exploration and exploitation, so during training it behaves a bit “timidly.” In the cliff-walking problem, it tries to stay as far from the cliff edge as possible, ensuring that even if exploration goes slightly wrong, it still remains in a safe region. In addition, because the policy uses the \(\varepsilon\)-greedy algorithm, the policy keeps changing as the value of \(\varepsilon\) shrinks, so the policy is unstable.
Q-learning is a typical off-policy algorithm. It has two policies, the target policy and the behavior policy, and it separates the two. Q-learning can boldly use exploratory trajectories collected by the behavior policy to optimize the target policy, which makes it more likely to discover the best strategy. The behavior policy may use the \(\varepsilon\)-greedy algorithm, but the target policy is greedy: it directly adopts the best strategy based on the data collected by the behavior policy, so Q-learning does not need to balance exploration.
Cliff Walking: Sarsa vs. Q-Learning in Python