Embedded AI Project: On the "Place" of Embedded Systems in the Future Information Society
Back in high school, I was already obsessed with computer hardware. Whenever manufacturers released new products, I would look them up immediately. I knew the differences between models inside out, and I even loved the exaggerated promotional images used by sellers. My Taobao shopping cart was a training ground for balancing cost and performance, while the PC-building requests of friends and relatives were my bugle call to put that knowledge to use. But the PC market had long since passed its era of rapid growth. High technical barriers and ecosystem monopolies led to product homogenization and very little real innovation, and over time I lost interest. Recently I built a small project with an 8051 microcontroller and, along the way, learned more about the many kinds of microcontrollers now on the market. Their low technical barriers and diverse use cases have produced a wild yet flourishing world of chips, memory, and peripherals, and that let me rediscover the old fun. That, in turn, made me want to build a small project that combines microcontrollers with machine learning.
The Future Information Society
When you want to build a PC, you can always invent a need for it. But if you want to build a practical embedded AI project, you first need to think about its background, its advantages, and why it should exist at all. My personal habit is to design from the top down. I want to sketch the outline of the future information society first, and only then design a product with an advanced concept. First, a conventional product will certainly lose to mature existing products. Second, if it is not forward-looking, I am not interested in making it.
To predict the future, it helps to look back at the past. In the early 2000s, the most popular games were Legend of Mir, Warcraft III, and Dota. People communicated on BBS forums, and internet cafes were an important place for ordinary people to get online. In the 2010s, the iPhone 4 appeared like a bolt from the blue, and from that point on smartphones became a standard item for almost everyone, marking the beginning of the mobile internet era. People could lower their heads and receive information anytime, anywhere, while information carriers evolved from text (2G, web novels) to images (3G) and then to video (4G, short videos). Meanwhile, the growth in request volume gave rise to technologies such as cloud computing and edge computing. As GPU computing power surged and video memory expanded dramatically, deep neural networks crushed support vector machines and became humanity’s dragon-slaying weapon for solving optimization problems.
From this we can summarize two important trends. First, network access keeps increasing. We have gone from needing to visit an internet cafe to being almost constantly online, and the next step should be the Internet of Things. Second, infrastructure and demand reinforce each other. More computing power catalyzed deep learning, network infrastructure enabled richer media, and massive human demand in turn forced innovation on the service side.
In the past, the mainstream service model was C/S. People applied cloud computing mainly because they wanted better servers.

Some people say the future information society will be 5G + IoT + ABC (AI, Big Data, Cloud Computing). I have doubts about some of those technologies, but I found that by combining these concepts with several other hot ideas, we can sketch part of the future application model and computing architecture for AI. Specifically, I organized their relationships and made the following modest prediction.

At the bottom are IoT devices. They connect to the internet through 5G, with low latency and high connection density, and generate unprecedented amounts of data. Take wind turbine monitoring as an example: the system may sample every few milliseconds and generate petabytes of data per day. Once collected, that data becomes excellent soil for cultivating AI models. During model development, there should be a unified and easy-to-use set of general operators, analogous to the x86 instruction set, to support both programming and hardware implementation, though this might eventually be replaced by AutoML.
The diagram on the right illustrates the computing model. Cloud computing can provide elastic, almost infinite computing power, making it suitable for tasks such as model training. Edge computing is more suitable for scenarios that need smaller but stable amounts of compute, such as continuously collecting images and running inference on them. But the two are not binary opposites. The dashed line represents the transition zone between them. For example, from the user’s perspective a CDN is cloud computing, but from the origin server’s perspective it pushes resources toward the edge.
The computing architecture of the future information society will be a multi-layer, heterogeneous supercomputer. Future AI models will be trained on top of the data layer and then deployed to computing nodes at different levels as needed.
The “Place” of Embedded Systems
Now that we have analyzed the overall architecture of the future information society, let’s take a closer look at the role of embedded systems within it and how they can be combined with AI.
Advantages
Real time and high reliability
As terminal nodes that collect data in real time, embedded systems can process and compute directly on the data. This not only guarantees computation time in theory, but also avoids trouble caused by network errors. In fields such as vehicle control and aerospace, hard real-time systems are often required. Therefore, embedded systems originally designed for mechanical control may consider introducing AI for tasks whose correctness requirements are not so strict, though the scope still feels limited.
Privacy protection
Sending data to the cloud introduces the risk of information leakage. More importantly, microcontrollers cannot run complex encryption algorithms, so data can be intercepted very easily.
Lower bandwidth cost and low power consumption
For Chinese companies, upstream bandwidth is extremely expensive. In the wind-turbine example above, if all data is sent to the cloud for analysis, it will consume a great deal of time and bandwidth cost. Compared with that, the deployment and power cost of a local AI chip is negligible. Therefore, data abstraction is a highly promising application scenario for embedded AI. For example, in security monitoring, the system could send only abstracted information such as time plus headcount to the cloud instead of the full video stream.
Challenges
Space and time complexity
Machine learning models usually have a large number of parameters, which consume memory, and a high computational cost, which consumes CPU. That is often too much for the limited performance of embedded systems. To address this problem, @ZhihuiJun tried running a neural-network gesture-recognition model on a Cortex-M MCU.[2.]
What is the minimum hardware performance needed to run inference on a CNN model?
Recently I wanted to combine some of my earlier embedded-microcontroller experience with the deep-learning work I have been doing lately. Around that time I also saw news that the new iPhone and the next-generation Pixel seemed likely to add hands-free gesture recognition, so the idea emerged.
To make a CNN run successfully on a Cortex-M MCU, the model used here was an FCN network with fewer than 10 layers. Even so, for a microcontroller with a clock speed under 100 MHz and under 100 KB of SRAM, it is still extremely demanding. Without quantization, real-time performance is impossible.
Tedious programming
Different vendors have introduced their own NPUs for AI computing. Programmers therefore have to relearn different interfaces and write programs from scratch for each chip.
Research Directions
Model simplification: Algorithmic work can include model quantization, distillation, pruning, and so on.
General operator set: Operations that virtually all NPUs must implement, such as matrix multiplication, convolution, pooling, and activation, can be unified into a common operator set, which would greatly facilitate both software and hardware development.
Hardware-software co-design: In [1.], Google gives the following definition:
The initial idea behind co-design was that a single language could be used to describe hardware and software. With a single description, it would be possible to optimize the implementation, partitioning off pieces of functionality that would go into accelerators, pieces that would be implemented in custom hardware and pieces that would run as software on the processor—all at the touch of a button.
This is an extremely forward-looking idea. It is very difficult to realize, but we can already start moving toward it.
Project Direction
For the project I want to build, I have the following goals:
- A striking appearance
- An advanced concept
In line with the ideas summarized in the previous article. - A degree of practical usefulness
- Original work
- Integration with machine learning
Hardware Selection
System-level Platforms
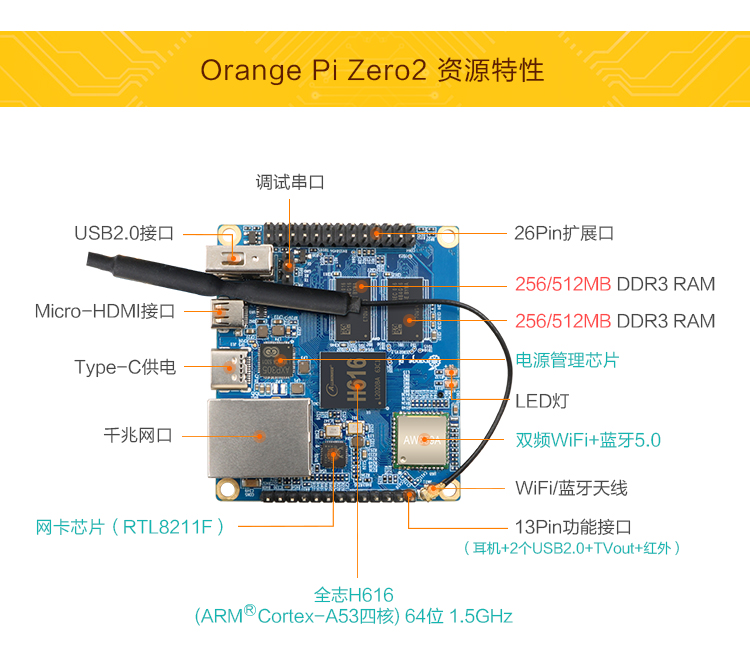
Running a complete Linux system is basically the same as having a miniature PC. You can write high-level languages such as Python, so programming is naturally the easiest on this type of platform. It is also convenient to provide upper-layer network services such as HTTP and DNS, and image-processing performance is strong. Some boards can even support 4K output. They are commonly used for soft routers, internet TV, personal servers, and similar tasks. Typical products include the Raspberry Pi, Orange Pi, and NanoPi, and the price can be quite low.
However, ordinary CPUs do not have much advantage for running deep-learning models. Calling network APIs should usually be considered first, which may weaken the edge-computing advantage. Another issue is that using a system-on-chip platform for small tasks is rather wasteful.
Traditional MPU
Typical examples include STM32. It is the cheapest and also the weakest in performance. Building an AI application with it would still be meaningful, but the input-output ratio is not high, and limited I/O makes real practical value hard to achieve.
High-performance MPU
There are currently several AI-enhanced MPUs on the market. One of the best is Canaan’s K210 chip: 0.3 W power consumption, 28 nm process, up to 1 TOPS of compute, and a price of 3 US dollars. It almost balances the impossible triangle of performance, cost, and power consumption. It is based on the 64-bit RISC-V architecture, has dual cores at 400 MHz, includes hardware implementations of convolution and FFT, and supports AES and SHA256 for security. Overall it feels close to a local optimum in IC design, and the commercial use of open-source RISC-V looks especially appealing in the current environment. Its main drawback is that it has only 8 MB of memory, and its implemented neural-network operators are not especially well designed.
More details on the K210: https://github.com/kendryte/kendryte-doc-datasheet
There are Sipeed development boards available for it.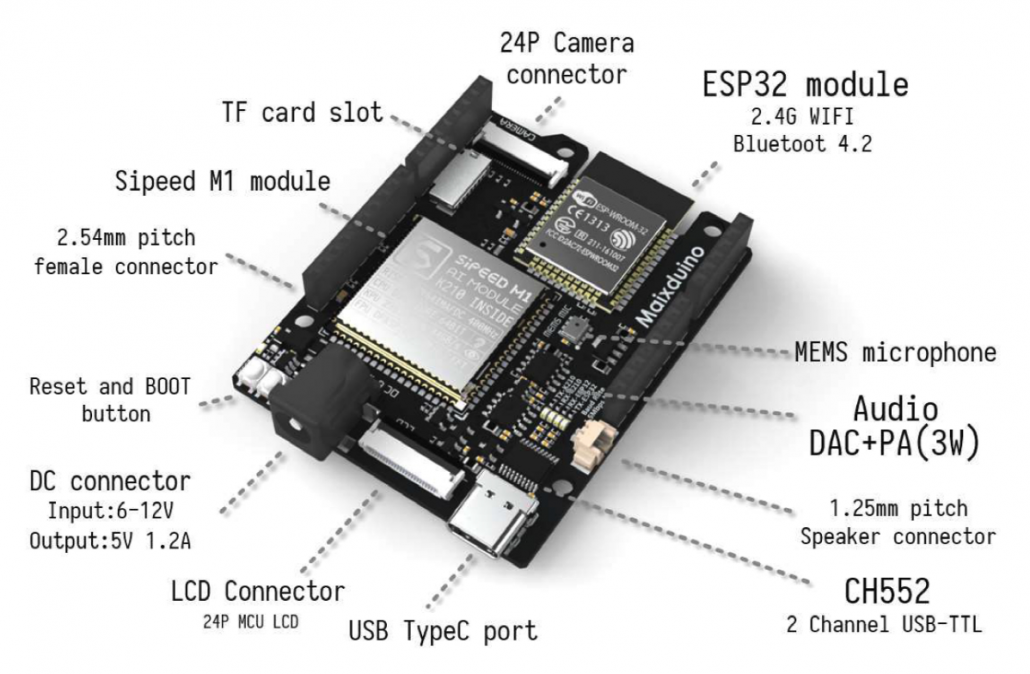
References
[1.] De Michell G, Gupta R K. Hardware/software co-design[J]. Proceedings of the IEEE, 1997, 85(3): 349-365.
[2.] http://www.pengzhihui.xyz/2019/07/20/m4cnn/
Embedded AI Project: On the "Place" of Embedded Systems in the Future Information Society