Quant4.0 (IV): System Integration and a Simplified Multi-Factor Quant Framework
In this section, we revisit Quant 4.0 from a systems perspective and explore how all of its components can be integrated into a single architecture. The figure below shows a suggested Quant 4.0 system framework, including an offline research system for quantitative research and an online system for live quantitative trading.
This article is a partial translation and adaptation of the paper Quant 4.0: Engineering Quantitative Investment with Automated, Explainable and Knowledge-driven Artificial Intelligence. Original paper
Quant4.0 (I): An Introduction to Quantitative Investing, from 1.0 to 4.0
Quant4.0 (II): Automated AI and Quantitative Research
Quant4.0 (III): Explainable AI, Knowledge-Driven AI, and Quantitative Research
Quant4.0 (IV): System Integration and a Simplified Multi-Factor Quant Framework
Offline Research System
The Quant 4.0 offline quantitative research system is designed to improve research efficiency. It contains multiple layers, including the hardware layer, raw data layer, meta-factor layer, factor layer, and model layer, as well as modules such as a high-performance computing cluster, data system, cache system, data preprocessing, automated factor mining, knowledge-based systems, large-scale data analytics, AutoML, and risk simulation.

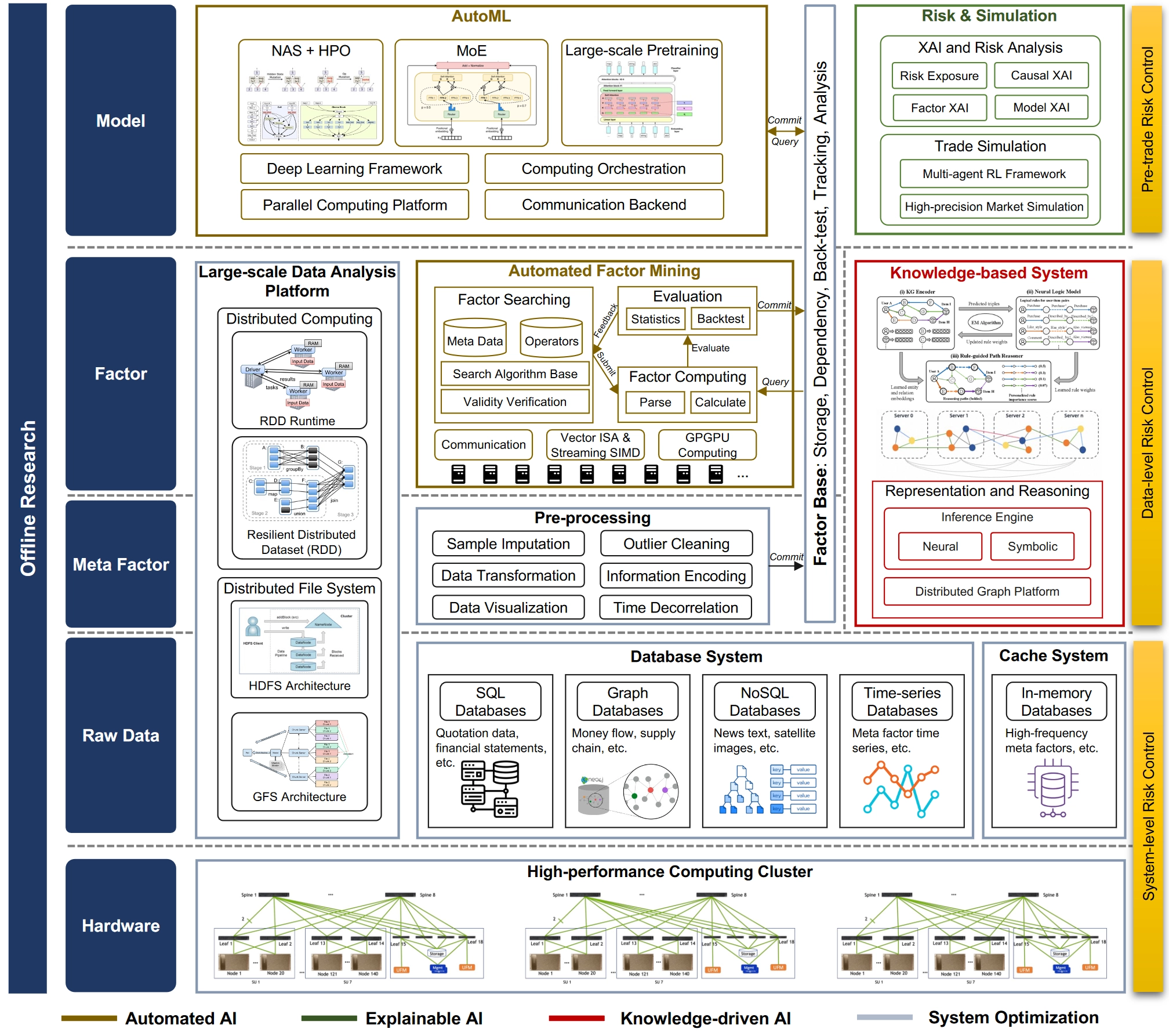
Hardware Platform Architecture
The underlying hardware platform for offline research is a high-performance computing cluster composed of many compute nodes with shared storage [267], connected through high-bandwidth networks [268]. Combining many nodes aggregates computing power across the cluster and supports large-scale quantitative workloads. In practice, however, communication bottlenecks often constrain scalability [269]. To address this, the cluster network topology adopts a hierarchical structure, where neighboring compute nodes are connected through lower-level switches to improve overall throughput.
Quant research must avoid look-ahead bias and adapt to style shifts, so factor computation and modeling inevitably depend on local data. If maximum efficiency is the goal, locality should already be considered at the hardware level.
Data System Design
The data layer of Quant 4.0 is responsible for collecting massive amounts of financial data and providing data management and query services to upper-layer applications. Because financial data is heterogeneous and multimodal, different types of database systems are needed to manage different data types. Examples include SQL databases [270], time-series databases [271, 272], NoSQL databases [273], and graph databases [274].
SQL databases store and manage data that follows the relational model described in [270], where data is organized into tables. Most traditional financial data, such as quote data and financial statements, can be represented in this way and are well suited to SQL systems.
Graph databases [275] are designed to store and manage graph-structured data consisting of nodes and edges. Financial entities are linked through many kinds of relationships, such as fund flows and supply-chain relations, so graph structure is common in financial data. These links may reveal latent patterns shared within neighborhoods. Graph databases can be used to store and manage economic graphs, financial knowledge graphs, and financial behavior graphs.
NoSQL databases [273] store non-tabular data such as key-value pairs, documents, and wide columns. They are suitable for managing financial text and image data, such as annual report text, news text, social-media text, satellite images, and drone imagery.
Time-series databases [272] are designed for fast access, computation, and management of time-series data. Their engines are optimized for real-time time-series processing, such as stock tick streams and high-frequency factor computation. In addition, the large volume of financial data demands efficient distributed storage systems to speed up access. To further improve read/write performance for high-frequency tick data such as limit order books, in-memory databases [276] can be used as a cache for the most frequently accessed data, saving transfer time between disk and memory.
Beyond layer-specific components, the data layer, meta-factor layer, and factor layer share a large-scale data processing platform that provides complete solutions and convenient abstractions for many data-driven tasks. Key components include distributed file systems, which offer reliable data access for distributed storage, and distributed computation engines, which provide simple and efficient programming interfaces for parallel computation across many nodes. Concretely, distributed file systems such as HDFS [264] use an architecture with name nodes and data nodes, replicating data across multiple data nodes for fault tolerance. Distributed compute engines such as MapReduce [277], and its open-source implementations including Hadoop [278] and Spark [260, 261], provide programming models for parallel workloads. By abstracting parallel tasks into primitive operations such as map and reduce in MapReduce or transformations in Spark, these tools remain convenient for developers while general enough to handle many common parallel programming tasks.
Factor Mining System
Raw data comes in many formats, but factor mining requires a unified input representation. Corresponding to the workflow in Figure 12, the meta-factor layer preprocesses raw data from different modalities into meta-factors with unified structure and appropriate values. The factor layer then builds the automated factor-mining engine and pipeline. The factor-mining algorithms themselves were introduced in §2.2.1; here the focus is how to implement factor mining at scale from a systems perspective, especially how to improve system efficiency so that more “good” factors can be discovered per unit time.
- The factor-mining system needs a parallel architecture to improve computational efficiency.
- During factor generation, syntactic validity should be checked in real time to reduce wasted CPU time on invalid factors.
- Factor diversity should also be controlled in real time to reduce redundant computation on near-duplicate factors.
The entire system is supported by distributed execution and compute acceleration. Distributed tools such as message queues and distributed caches allow asynchronous parallel execution across nodes, which ensures scalability. Compute acceleration techniques such as CPU vector and SIMD instructions, together with large-scale parallel computation on general-purpose GPUs (GPGPUs) [279], significantly improve the efficiency of dataframe operations and therefore the productivity of the whole platform. The meta-factor layer, factor layer, and model layer all connect to a factor repository: an integrated platform for storing, computing, managing dependencies, backtesting, tracking, and analyzing all factors, where model outputs are also treated as factors. Meta-factors generated from raw-data preprocessing are committed to the factor repository directly as dataframes with proper descriptions of data sources and preprocessing methods. Factors produced by automated factor mining are submitted as symbolic expressions whose operands are other factors already in the repository. Model outputs from the model layer can likewise be seen as special machine-learning factors and stored together with their input factors, model architecture, hyperparameters, and training descriptions.
Treating every datetime-asset hierarchy as a factor is an idea worth borrowing.
Knowledge-Based System
Parallel to the factor-mining system, the overall architecture also contains a knowledge-based subsystem to support knowledge-driven AI, as discussed in Section 4. This subsystem includes two modules: a knowledge base for knowledge representation and an inference engine for reasoning. Concretely, a distributed graph computation platform serves as the knowledge base for storing large-scale financial behavior graphs, while the inference engine is built on top of it for downstream financial reasoning and decision-making. Compared with traditional small knowledge bases, the financial behavior graph in Quant 4.0 could eventually grow to billions of nodes and edges, so a flexible and scalable architecture [280, 281] is required to store and manage large dynamic graph data. That means a distributed graph computation and management platform is needed to partition the entire graph into subgraphs distributed across nodes in the cluster. Because knowledge graphs are sparse, the partitioning should maximize data locality, so nodes in the same partition are more densely connected than nodes across partitions [282]. Knowledge graph embedding and rule-based symbolic reasoning can then be implemented on top of this platform.
Modeling System
The model layer is responsible for automatically generating machine learning models, together with the corresponding risk analysis and backtest/simulation procedures, before deployment into live environments. This layer therefore includes two main components: an AutoML module and a pre-trade risk analysis and simulation module. The AutoML module runs automated model-generation algorithms on a large-scale distributed deep learning system. The bottom of its technology stack includes parallel computing platforms such as CUDA [283] and communication backends such as MPI [284], which provide standard interfaces for communication among nodes in distributed systems. The next layer includes deep learning frameworks such as PyTorch [285], which provide basic interfaces for training and inference, relying on hardware-accelerated linear algebra and automatic differentiation engines. Above that, compute orchestration systems such as Pathways [286] combine low-level communication primitives with framework features to realize higher-level parallelism such as model parallelism and pipeline parallelism, and expose them through standard interfaces. The top layer contains implementations of model-generation algorithms such as neural architecture search and hyperparameter optimization (NAS+HPO) [287], mixture of experts (MoE) [265], and large-scale pretraining [288, 289].
The risk and simulation module identifies and analyzes the model’s potential risk exposures before deployment into live trading. It applies explainable AI techniques to analyze factors, models, and causal relationships, revealing nonlinear risk exposures that are more complex than ordinary exposures explained by BARRA-style models. In addition, a market simulator [290] is used to test trading strategy performance more accurately than historical backtests alone, whose results may be biased by historical data. Concretely, the simulation environment can be built with multi-agent reinforcement learning [291, 292], where agents imitate different kinds of market participants [293].
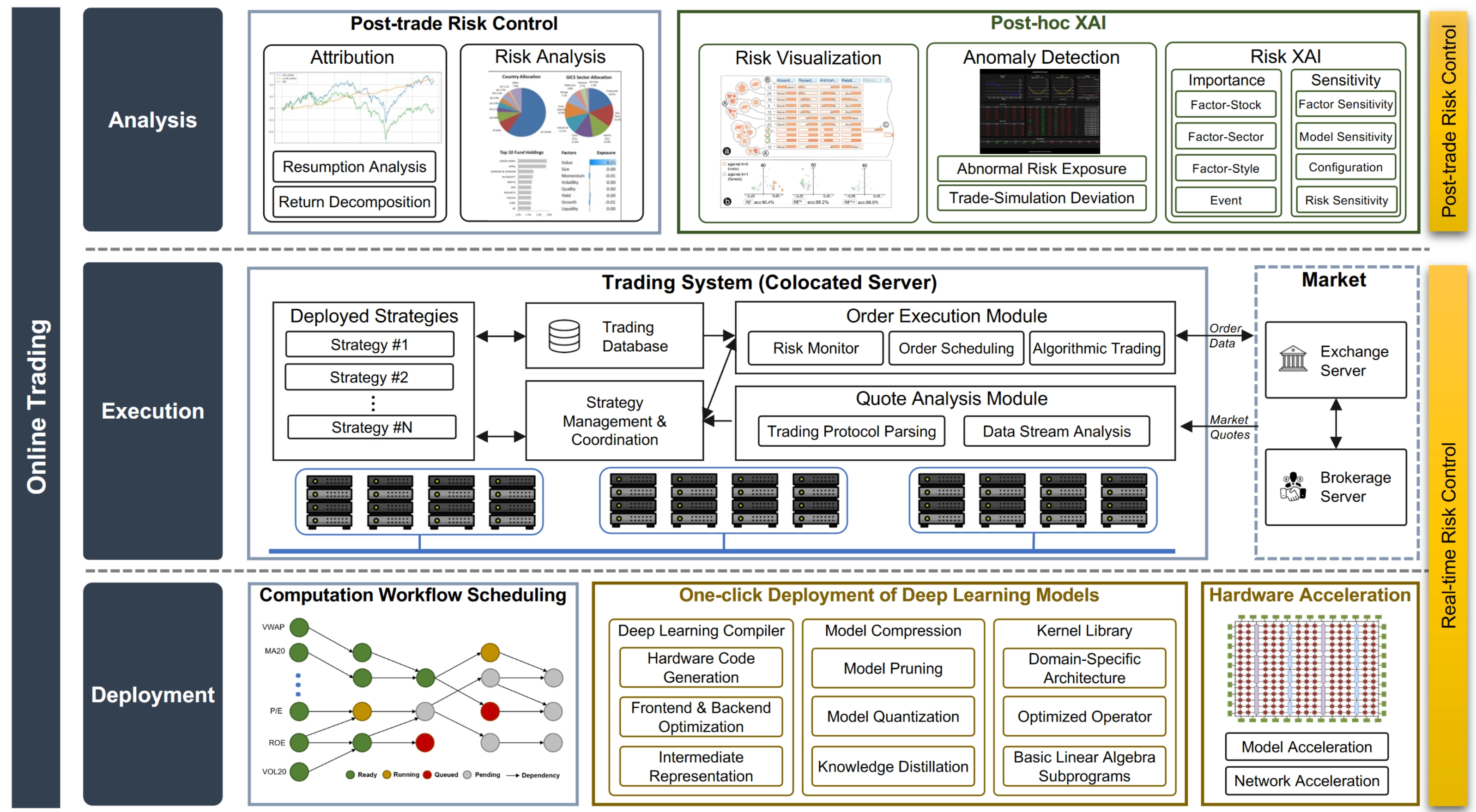
Online Trading System
The online trading system focuses on deploying strategies into live markets and analyzing executions afterward. Its main goals are low latency and high execution efficiency. It consists of three modules: deployment, trading, and analysis.
Model Deployment
The deployment layer is designed around the idea of “one-click deployment.” It includes a compute scheduling module, an automatic deployment module, and an optional hardware acceleration module. The compute scheduling module arranges an efficient execution order based on the intrinsic data dependencies among factors, forming a directed acyclic graph (DAG) of factor dependencies. Within this scheduling system, a factor starts computing only after all its predecessors on the DAG have been computed. This scheduling problem is tedious and should be automated for several reasons:
- Offline factor dependencies and online factor dependencies must be synchronized in real time and kept consistent.
- The number of factors can grow rapidly. Once millions of factors accumulate, manual deployment becomes a nightmare.
- Adding, deleting, and updating factors is routine maintenance work, and correct dependency management is essential.
Reasonable.
From an algorithmic perspective, compute scheduling can be seen as topological sorting on a dependency DAG. In practice, the scheduler coordinates system components and arranges execution according to the DAG order. In common implementations of such systems [294], asynchronous scheduling is adopted to improve overall efficiency, allowing later steps to begin immediately after their prerequisites finish.
The automatic deployment module is responsible for moving deep learning models trained offline into online trading. It implements the algorithmic techniques discussed in Section 2.4. In addition to deep learning compilers and model-compression engines, it also relies on optimized hardware kernel libraries that provide highly optimized implementations of common data-processing and modeling functions for specific hardware. Popular examples include cuDNN [295] and MKL [296]. Functions in these libraries usually include basic linear algebra subroutines (BLAS) [297] for scientific computing, as well as optimized operators for deep learning such as 3D convolution. These implementations are optimized for domain-specific architectures [298] so the underlying hardware can be used to its fullest potential. The hardware acceleration module aims to improve efficiency further using specialized hardware such as FPGA-based acceleration. Strategy components implemented on FPGAs, such as network protocol stacks or machine-learning models with custom logic, can bypass redundant logic that is unavoidable on general-purpose hardware and thereby achieve lower latency. The cost is that deployment on specialized hardware typically requires major engineering effort, which is why high-level synthesis techniques [300, 301, 302] have been developed to generate register-transfer-level code directly from higher-level strategy representations.
Trade Execution
The execution layer converts trading decisions into orders that are actually sent to the exchange. Its goal is to minimize latency so the system can capture fleeting market opportunities. Latency can be decomposed into transmission latency, which is the delay in signal communication between the trading server and the market server, and computational latency, which is the delay between market-data reception and order submission. To reduce transmission latency, trading systems are usually colocated with market servers, for example in broker-provided cabinets or racks. To reduce computational latency, the full strategy pipeline must be optimized through software and hardware acceleration, from data collection all the way to order execution.
Trade Analytics
The analytics layer monitors strategy execution and performs follow-up analysis for adjustment. It includes a post-trade risk-control module for conventional performance monitoring and a post-trade explainable AI (XAI) module for interpreting strategy behavior from the perspective of AI. The post-trade risk-control module performs return and risk attribution to analyze strategy performance and reveal the internal risk structure hidden inside machine-learning black boxes. The post-trade XAI module provides deeper analysis and interpretation by examining the importance and sensitivity of all strategy components, delivering more thorough risk analysis and visualization.
Note Risk control is one of the core tasks of quantitative investing and one of the main considerations in system design. In the engineering framework proposed here, risk control runs through the entire architecture. System-level risk control appears in the hardware and raw-data layers, where the reliability and stability of infrastructure and raw inputs are the first priority. Data-level risk control appears in the meta-factor and factor layers, where the quality control and management of factors and knowledge are emphasized. Pre-trade risk control appears in the model layer, where robustness and interpretability are required. Real-time risk control appears in the deployment and execution layers, where trading behavior is constrained to prevent unexpected events. Post-trade risk control appears in the analytics layer, where detailed analysis provides a comprehensive and reasonable understanding of performance.
A Simplified Multi-Factor Quant System
Based on the original paper, this section proposes a quantitative alpha-investing system tailored to individuals or very small organizations. Its main features are:
- extensive reuse of open-source community resources;
- a streamlined architecture with controllable cost;
- lower labor requirements through the use of machine learning.

Quant4.0 (IV): System Integration and a Simplified Multi-Factor Quant Framework