A Hitchhiker's Guide to the Age of Big Data
Don’t Panic
Introduction
There is, or will soon be, a problem in this society: most people produce data most of the time, are governed by data at the same time, and yet know almost nothing about it. Humanity has produced a large number of articles in response, but most of them begin with combinations of mathematical symbols, which is strange, because the things that are ignorant are not those symbols.
The purpose of this article is to give you everything you need to enter the age of big data, even if you have never heard of calculus. It may look long, and it certainly contains some false or at least imprecise statements, but it surpasses more advanced and old-fashioned academic works in two extremely important ways.
First, it is completely free. Second, at the beginning, in large friendly letters, it says “Don’t Panic”. Its content also lets readers skip difficult formulas and directly obtain the high-level picture. I would call this approach math-free.
Artificial Intelligence
In today’s world, few terms are more widely repeated than AI, or Artificial Intelligence. Yet very few people actually know what artificial intelligence is. Most of the time, the phrase functions as a spell for sounding impressive:
SenseTime takes “persist in original innovation and let AI lead human progress” as its mission and vision.
- SenseTime, a famous AI startup
It is also looked down on by insiders:
You are the one doing AI. Your whole family is doing AI.
- Dr. Xu Li, founder of SenseTime
In fact, the concept is so broad that definitions vary widely. If we use rationality vs. human-likeness and process vs. outcome as two axes, four definitions appear:
- Thinking like a human
- Thinking rationally
- Acting like a human
- Acting rationally
AI in films and novels is usually defined from the perspective of thinking: it has mind and consciousness and can act according to its own intentions. In academia this is called Artificial General Intelligence (AGI). AGI is widely known because of art and fiction, but unfortunately it is not a mainstream research direction because of technical limits and ethical issues. Discussing AGI has something of the same unserious flavor as discussing immortality, and it is hard to speak of “achieving” it anytime soon. Still, David Silver, Chief Scientist at DeepMind, argues that AGI can be realized by combining deep learning (DL) and reinforcement learning (RL), that is, AGI = DL + RL. These two concepts will also appear later in this article.
Along the path of “acting like a human”, the classic example is the Turing Test proposed in 1950 [4]: let a human chat with a program by text and see whether the program can pass as human. In 1966, Joseph Weizenbaum created a program called ELIZA [5] that seemed to pass the test. It did so through evasive and vague replies, essentially lowering the bar of the conversation. Given how hard it is to define the lower bound of real human intelligence, that is not very meaningful.
The AI that has been and will continue to be deployed at scale consists of programs that can “act rationally” in a specific domain, such as face recognition, machine translation, or board games. Here are two formulations of that definition. All the AI discussed below follows this interpretation.
Intelligence is the computational part of the ability to achieve goals in the world. Varying kinds and degrees of intelligence occur in people, many animals and some machines.[1]
Ideally, an intelligent agent takes the best possible action in a situation.[2]
That is, artificial intelligence is an outcome rather than a method. We use other technologies to reach that outcome. For example, AI can be built through simple hand-written expert rules, but that is not the mainstream approach. The core method in this field today is called machine learning.
Usually, we say that we work on machine learning.
- Dr. Xu Li, founder of SenseTime
Machine Learning
In 1997, Mitchell gave a formal definition of machine learning:
Machine learning (ML) is the study of computer algorithms that improve automatically through experience.
For a class of tasks T and a performance measure P, if a computer program improves its performance at T as measured by P through experience E, then it is said to learn from experience E.[3]
Programs improve through experience. This definition may sound almost as broad as the definition of artificial intelligence. More concretely, the ultimate proposition of machine learning is to turn real-world problems into optimization problems: write down a mathematical performance measure, then try to find the optimum.
When turning real problems into mathematical form, the first step is always approximation and compromise, because mathematics and computers cannot fully express reality. After that approximation, the set of all remaining input-output mappings is called the hypothesis space. For example, if we toss a coin and predict the result, the hypotheses in the hypothesis space may only output heads or tails, while in the real world the coin could also land on its edge. A particular hypothesis in that space can be called a model, such as a hypothesis that always predicts heads.
The process of learning a model from data is called “learning” or “training”. It is completed by executing some learning algorithm. We can view learning as a search for the optimum within the hypothesis space [7]. There are thousands of machine learning algorithms, each with its own strengths, but if we strip away the real problem context, mathematics tells us that their expected performance is the same, as stated by the No Free Lunch theorem [6]. So it only makes sense to discuss whether an algorithm is good or bad for a specific problem. There is no universally best algorithm.
Once an algorithm has been chosen, training, that is the “self-improvement” mentioned above, eventually produces a usable result, namely a fixed hypothesis called a model. It accepts input and returns output. For example, if a program takes height and weight as input and predicts gender, the program is a model. The algorithm behind it could be something like counting how often the three variables co-occur in the dataset, then, for a given height and weight, looking up the male-female ratio and returning the more likely one, in the hope of doing better than random guessing.
After reading all this, you may still feel a bit lost: how is machine learning actually implemented? In practice the methods are varied, but they can be grouped into three basic learning paradigms, which will be introduced one by one below:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
The frequently mentioned term deep learning is not a paradigm. It is simply one method inside machine learning. If machine learning is an important way to achieve artificial intelligence, then deep learning stands to machine learning as machine learning stands to artificial intelligence. The performance breakthroughs brought by deep learning were so dramatic that they directly triggered the AI boom of recent years.
All of the concepts above can be summarized in one diagram:
Supervised Learning
We begin with supervised learning, the most intuitive paradigm. In supervised learning, you must have a labeled dataset, or at least treat some columns in structured data as prediction targets. The algorithm first learns from labeled data, that is, the training set, to adjust the model, and then applies the model to unlabeled data, that is, the test set. Supervised learning mainly contains two categories of tasks: classification and regression.
Consider the following dataset:
| Id | Gender | Height(cm) | Weight(kg) |
|---|---|---|---|
| 1 | Male | 187.6 | 99.7 |
| 2 | Male | 174.7 | 66.9 |
| 3 | Male | 188.2 | 87.7 |
| 4 | Male | 182.2 | 90.7 |
| 5 | Male | 177.5 | 85.1 |
| 6 | Female | 149.6 | 42.1 |
| 7 | Female | 165.7 | 58.3 |
| 8 | Female | 161.0 | 54.0 |
| 9 | Female | 163.8 | 52.9 |
| 10 | Female | 157.0 | 53.5 |
Now we can try to solve a regression problem that predicts a continuous value: use male height \(x\) to predict weight \(y\). Although the example is simple, it shows a complete supervised learning workflow.
- Assume a relationship between \(x\) and \(y\)
- Define an objective function to evaluate the model
- Adjust the model parameters to optimize the objective
In this example, the procedure is:
- Assume a simple linear relationship and use the line \(y=ax+b\)
- Use mean squared error as the objective, that is, minimize the sum of squared vertical distances from the points to the line
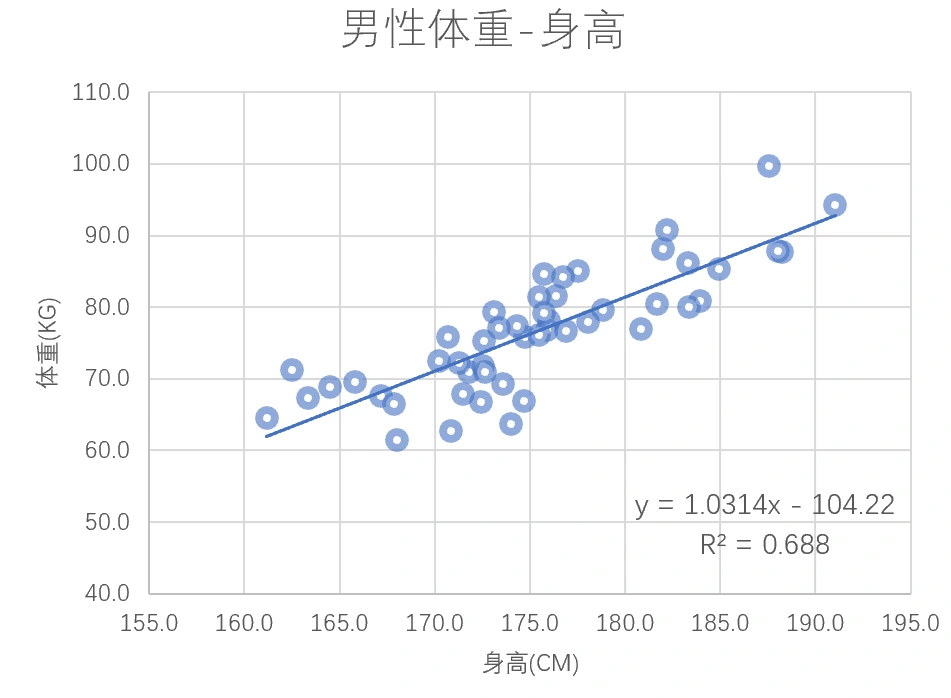
- Use least squares to find the best line. The final model is \(y=1.0314x-104.22, R^2=0.688\). The coefficient \(R^2\) is a common metric for regression models. It lies between 0 and 1, and higher values indicate a better fit.
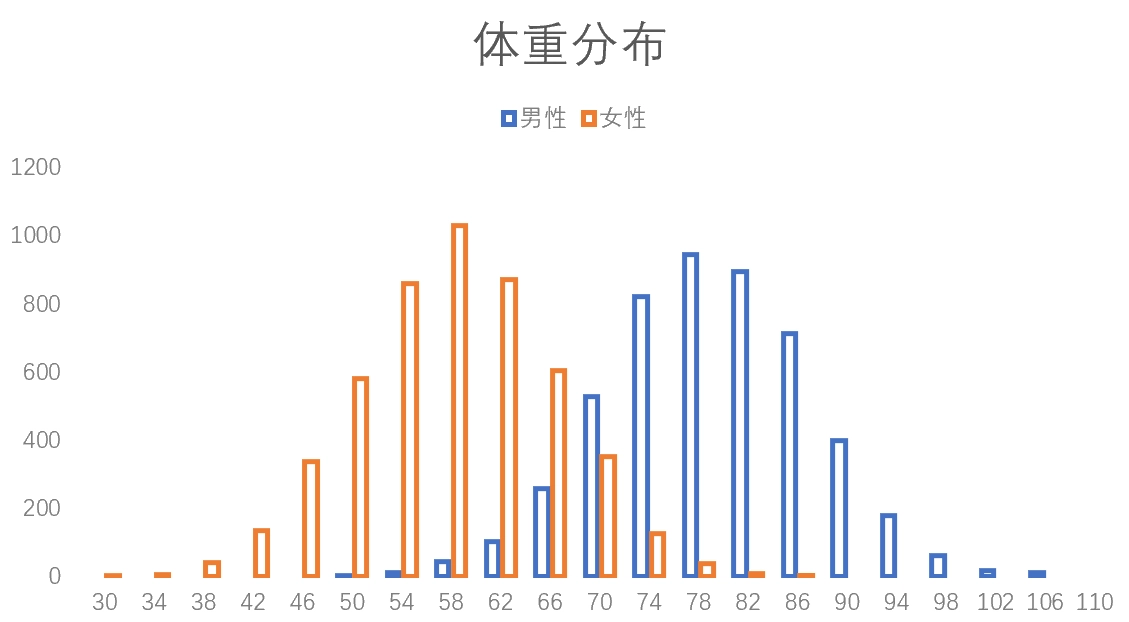
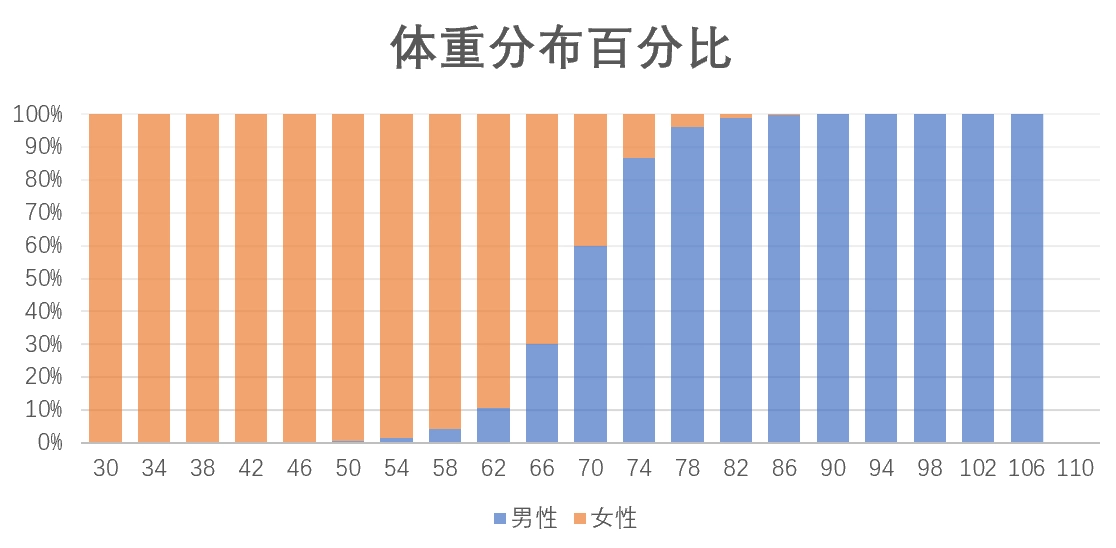
The same dataset can also be used for a binary classification problem: input weight \(x\) and output gender \(y\). The classic frequentist approach is to first draw the weight distributions of the training set and treat that as the true distribution of the world. For a given new \(x\), use the male-female proportion at the corresponding position in the figure as the predicted probability. For example, if the weight is 70 kg, then we predict a 70% probability of being male. The same logic extends to higher-dimensional inputs such as height, weight, and age together.
If you want to learn more about algorithms for classification, you can also refer to other articles on HeThink:
- ID3 decision tree https://heth.ink/2020/id3/
- Logistic regression (LR) https://heth.ink/2020/logisticregression/
Unsupervised Learning
In the real world, labeled datasets are rare. Most real data is unlabeled and messy. Labeling by hand is not only expensive but often impossible. For that reason, machine learning contains a family of algorithms that can learn from data and output models without relying on ground-truth labels. This family is called unsupervised learning. If supervised learning mainly solves regression and classification, then unsupervised learning mainly handles clustering and dimensionality reduction.
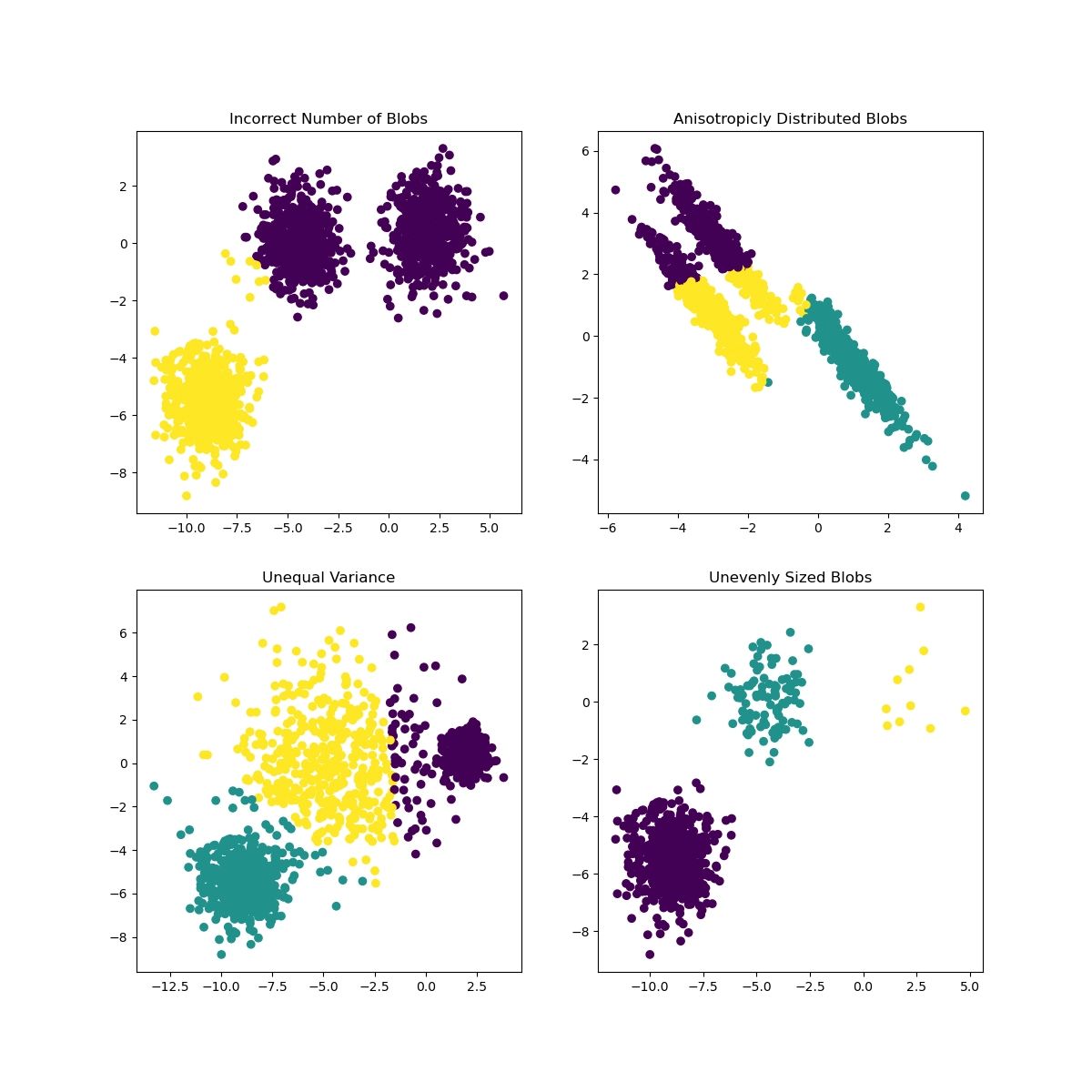
Start with clustering. In two-dimensional or three-dimensional space, humans can easily separate points that form regular groups, but in high-dimensional space that becomes difficult. Clustering algorithms automate this process. As shown in the figure [8], different prior knowledge, meaning different algorithms and parameters, combined with different data distributions, can lead to very different clustering results.
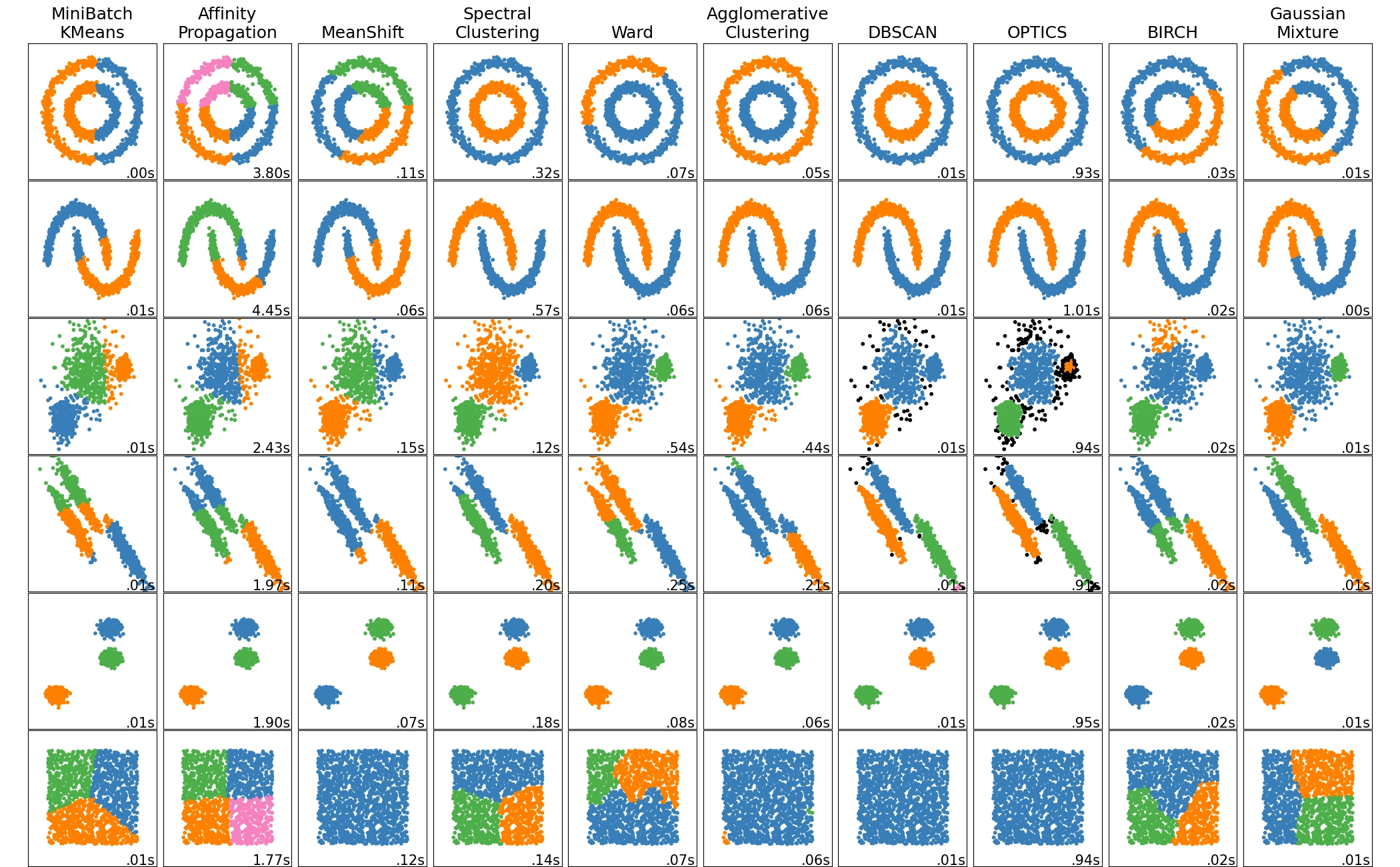
Another class of tasks is dimensionality reduction, among which the most famous example is the cocktail party problem. The Cocktail Party Problem, proposed in 1953, is a classic task in speech recognition. When people talk at a cocktail party, their voice signals overlap, and a machine must separate them into independent signals.
Reinforcement Learning
Reinforcement learning studies how to train an agent so that it can maximize reward in a complex and uncertain environment. As shown in the figure, the agent receives observations from the environment, takes actions according to a policy, receives feedback, and gets a new state in return. Compared with supervised learning and unsupervised learning, reinforcement learning differs in two major ways:
- Observations from the environment are usually continuous and strongly correlated, so they do not satisfy the i.i.d. assumption.
- Reinforcement learning requires exploring the environment and receiving feedback in order to adjust the policy, and that feedback is often delayed. In supervised learning, every output can be scored as right or wrong or by the size of the error. In reinforcement learning, the quality of the current action may be unknowable until a hundred steps later.
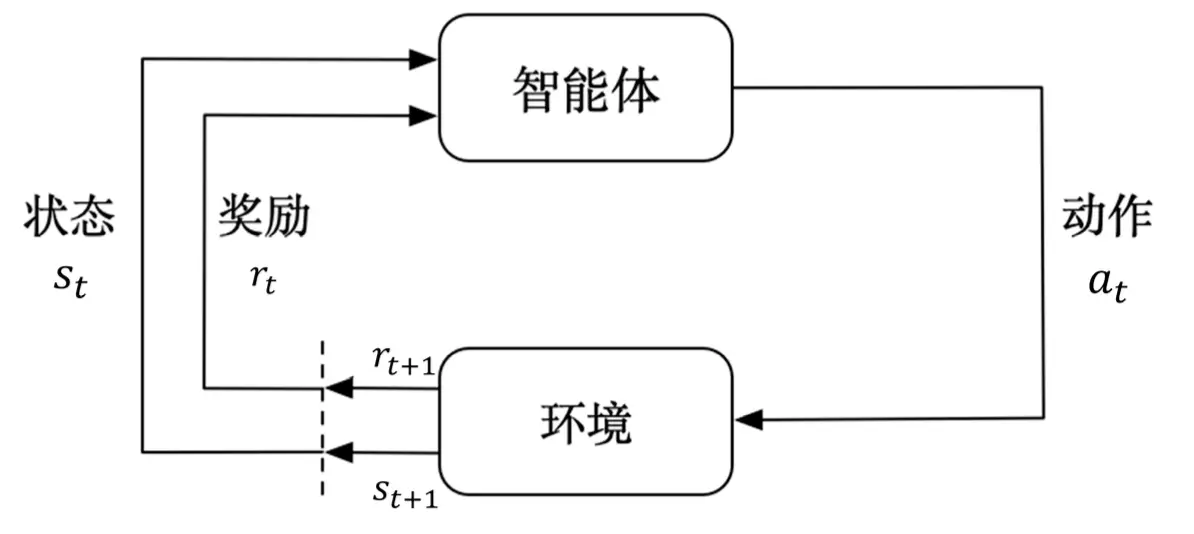
For a reinforcement learning agent, one or more of the following components may exist.
- Policy. The agent uses a policy to choose the next action.
- Value function. We use a value function to evaluate the current state. It measures how much entering a state will affect future rewards. The larger the value, the more favorable the state is for the agent.
- Model. The model represents the agent’s understanding of the environment and determines how the world evolves.
The agent must at least learn a policy or a value function in order to make decisions. Algorithms that learn the former are called policy-based agents. Those that learn the latter are called value-based agents. Algorithms that learn both are actor-critic agents. Learning a “model” is optional and depends on whether the next state and reward can be predicted. Reinforcement learning algorithms can also be divided into model-based and model-free methods.
References
[1.] Prof. John McCarthy of Stanford University http://jmc.stanford.edu/artificial-intelligence/what-is-ai/index.html
[2.] Russell, S., & Norvig, P. (2002). Artificial intelligence: a modern approach.
[3.] Mitchell, Tom (1997). Machine Learning. New York: McGraw Hill. ISBN 0-07-042807-7. OCLC 36417892.
[4.] Turing, A. (1950). Computing Machinery and Intelligence. Mind, LIX (236): 433-460.
[5.] Weizenbaum, J. (1966). ELIZA - a computer program for the study of natural language communication between man and machine. Communications of the ACM. 9: 36-45.
[6.] Wolpert, D. H. and W. G. Macready. (1995). “No free lunch theorems for search.” Technical Report SFI-TR-05-010, Santa Fe Institute, Santa Fe, NM.
[7.] Zhou Zhihua. Machine Learning [J]. 2016.
[8.] Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
A Hitchhiker's Guide to the Age of Big Data