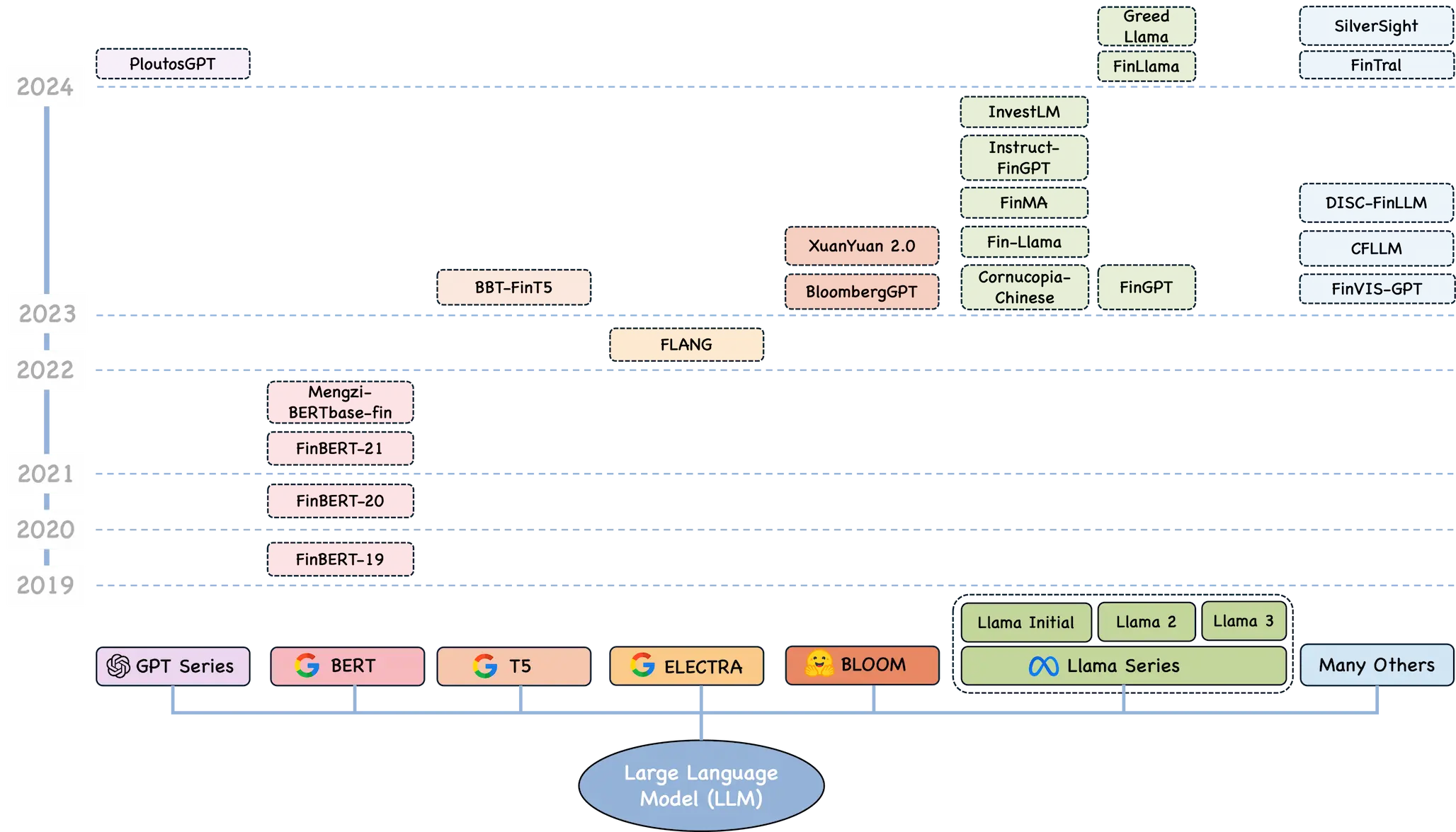
Trends in Large Language Models and Their Applications in Quantitative Investing
Large language models have become the hottest and fastest-moving frontier in computing since ChatGPT burst onto the scene at the end of 2022. LLMs have gradually shed the role of mere tools and become independent carriers of intelligence that can handle tasks on their own. In 2024, hundred-billion-parameter models such as Qwen2 and Llama3.1 were released one after another, and the performance of open-source models has moved steadily closer to that of closed-source systems. For quantitative researchers, a necessary question is how to combine LLM technology with financial applications to improve research and investment. This article first draws on Li Mu’s talk to discuss LLM trends and best practices, and then reviews specific application scenarios for LLMs in quantitative investing.
Large Language Models
Although large language models are two orders of magnitude larger than the machine-learning models people were used to before, they are still a natural extension of earlier methods rather than some discontinuous miracle. They obey the general laws of machine-learning model development. This section mainly draws on Li Mu’s August 2024 talk at Shanghai Jiao Tong University to discuss LLM trends and best practices.
Pretraining: Development Trends
Worldwide, the number of organizations that truly possess pretraining capability is actually very small. For most people, cost constraints mean that using existing pretrained models is the only practical option. The core view on future evolution is this: in the short run models will depreciate rapidly, and in the medium to long run progress will hit bottlenecks.
Moore’s law in the chip industry applies to LLMs as well. Roughly every year, the cost of training a model of a given size falls by half. That means we can expect a steady stream of bigger and better models in the near term, especially as Nvidia’s next generation of GPUs is deployed. It does not make much sense to obsess over the performance of any particular pretrained model, because the model’s value depreciates quickly, while the use cases built on top of it are what retain long-term value.
In the medium and long term, however, LLM capability improvements are likely to meet bottlenecks. The upper bound of model performance is determined by training data, and current LLMs have already consumed datasets on the order of 10T to 50T tokens, which is close to the limit of available internet-scale data. When scaling data volume further is no longer feasible, the only remaining route is to spend large amounts of money and labor cleaning existing data and improving its quality. There is no shortcut there, and no order-of-magnitude leap should be expected. Is continuing to expand model size feasible? Model size is constrained by memory capacity, and since single-card memory is unlikely to break far beyond 200 GB, publicly served LLMs will likely stay below roughly 500B parameters. Finally there is the model architecture. Whether viewed from the macro constraints of data and hardware or the micro perspective of architecture, it is hard to see where algorithmic innovation alone will produce a dramatic breakthrough.
Another point is that models that perform well on domain tasks must also have solid general capability. The phrase “industry foundation model” is mostly a false proposition.
Post-Training: What Matters Most
If pretraining an LLM from scratch is neither economical nor necessary, then what are the key points in post-training?
Application scenarios The model itself has no value; value is created by the application scenario. If the old quant logic was to combine data with formulas to produce an indicator, then factor mining in the LLM era may become a matter of “what question to ask in what context.” The application scenario and the question are where alpha comes from.
Data and algorithms To improve a model’s performance in a domain, the core requirement is high-quality structured data. Application scenarios and data are tightly bound to each other: the data you have determines which scenarios you can do, and the scenarios you want to do determine which data you need to collect. Once the data is fixed, choosing the right post-training algorithm becomes a technical problem. Algorithm performance depends on the data distribution, and there is no single universal answer.
Evaluation Good evaluation is half the battle. Evaluation is what lets researchers iterate and improve models. Quant research has a natural advantage here, because text data streams eventually map into investment decisions and can therefore be evaluated quantitatively. In many other domains, linguistic ambiguity makes accurate evaluation heavily dependent on manual judgment.
In short, the core of post-training is the accumulation of application scenarios, high-quality data, and improved algorithms.
Quantitative Applications
At its core, an LLM provides effectively unlimited cheap cognitive labor. The essence of LLM applications in quantitative trading is to capture the spread between LLM reasoning and human processing cost, and the size of that arbitrage is determined by the model’s intelligence level.
The rest of this section is an excerpted, translated, and commented summary of the Princeton and Oxford paper A Survey of Large Language Models for Financial Applications: Progress, Prospects and Challenges.
Text Work
Many earlier models, such as recurrent neural networks and especially long short-term memory models, had already shown some ability to understand language and perform text tasks [63]. Yet architectural limits made them struggle with long dependencies. In practice they had difficulty maintaining context over long text sequences, understanding complex expression, handling large datasets, and processing unstructured data efficiently [63], [64]. These limits are especially severe in finance, where document volume is huge and accurate, concise summaries are critical [65].
LLMs built on the Transformer architecture have substantially improved what can be done in this area. With self-attention as the key innovation, LLMs can process, understand, and generate text based on the vast datasets used in training [66], [67]. This breakthrough is crucial for overcoming the earlier difficulties. By effectively managing long-range dependencies and contextual information in large bodies of text, LLMs can compress complex financial narratives into concise summaries and extract relevant information while preserving key insights [66], [67].
Named entity recognition Named entity recognition is a subtask of information extraction and plays a crucial role in extracting meaningful information from diverse financial sources [87], [88]. In finance it is used to identify specific entities from news articles, financial reports, market summaries, and other sources, including company names, financial terms, tickers, financial indicators, and currency values [89]. This information matters for downstream tasks such as industry classification, sentiment analysis, credit scoring, fraud detection, and compliance reporting [90].
Although LLMs show remarkable generalization ability, they can impose high training and inference costs when processing long financial documents. To address this, Zhou et al. [102] propose UniversalNER, a method that uses target distillation and task-oriented instruction tuning to train cost-effective open NER student models. The approach not only reduces computational burden but also achieves impressive NER accuracy without direct supervision.
Constructing financial relationships Building financial relationships through tools such as knowledge graphs is a powerful way to organize and understand entities extracted from large and complex financial datasets together with the relationships among them [104]. A knowledge graph consists of interconnected descriptions of entities such as objects, events, and people, their attributes, and the relationships that connect them. This framework provides a structured representation of data relationships and supports more sophisticated downstream analysis [105], [106].
Which financial problems depend heavily on such graphs? That still needs to be accumulated through practice.
Text classification is essential for organizing and understanding vast amounts of unstructured financial data. It can be broken down further into subtasks such as industry or company classification and document or topic classification. By classifying and organizing this information effectively, firms and researchers can extract valuable insights and make better decisions. Combined with financial relationship building, these classification techniques are important for improving decision-making and analysis in finance.
Company or industry classification means grouping companies with shared characteristics such as business activity and market behavior into coherent but differentiated clusters. Identifying similar company profiles is a fundamental task in finance with applications in portfolio construction, security pricing, and financial risk attribution. Traditionally, analysts rely on industry classification systems such as GICS, SIC, NAICS, and Fama-French to identify similar firms [123]. However, these systems do not provide a way to rank companies by degree of similarity and require large amounts of manual analysis and data processing by domain experts [123].
More recently, a team at Blackstone [124] explored a new method that uses LLMs to classify companies. They studied pretrained and fine-tuned LLMs that generate company embeddings from SEC filings. Their goal was to evaluate whether the embeddings can reproduce GICS classifications, benchmark LLM performance across downstream financial tasks, and examine how pretraining objectives, fine-tuning, and model size affect embedding quality. The results show that LLM-generated embeddings, especially from fine-tuned Sentence-BERT models, can reproduce GICS industry and sector classification accurately and outperform them in tasks such as identifying similar firms through return correlation and explaining cross-sectional stock returns.
It is a very reasonable direction to extract common company characteristics from text with LLMs and feed them into a risk model.
Document or topic classification is another key subtask of financial text classification. It involves assigning financial documents or text, such as news articles [126], [127] or corporate filings [128], [129], to predefined topics. Alias et al. [130] proposed a new method that uses FinBERT to extract and classify topics related to key audit matters from the annual reports of companies listed on Bursa Malaysia. Likewise, Burke et al. [131] fine-tuned FinBERT to classify accounting topics across three unlabeled financial-disclosure sections, including notes to financial statements, management discussion and analysis, and risk-factor sections.
Sentiment Analysis
The arrival of LLMs marks an important milestone for financial sentiment analysis. These models have now proven effective across many tasks and offer several distinct advantages for FSA.
- LLMs are strong at interpreting the complexity of financial language, including informal expressions, emojis, memes, and domain jargon on social media and financial blogs [58], [60], [173], [174], [175], [151]. They are also skilled at recognizing subtleties such as sarcasm, irony, and industry-specific terminology, which matters for accurately analyzing sentiment across formats ranging from tweets to detailed financial reports [176], [6].
- The ability and future potential of LLMs to process multimodal data, including images, audio, and video, is critical for comprehensive sentiment analysis in financial settings such as earnings calls [155] and FOMC meetings [177]. This makes it possible to incorporate nonverbal cues and visual information into sentiment analysis [37].
- LLMs can process large document collections and perform comprehensive analysis on long reports and articles, helping ensure that no sentiment-bearing text is missed. This is especially valuable for annual reports, earnings-call transcripts, and lengthy financial narratives [157].
Social media Platforms such as Twitter, Reddit, StockTwits, financial blogs, and Weibo have become important data sources for financial sentiment analysis. They matter because they contain large quantities of real-time unstructured text reflecting public views on financial markets, specific stocks, and the broader economy. The immediacy and openness of these discussions make them valuable for capturing market sentiment, which can help predict future market movement. Su et al. [150] used BERT to extract sentiment and semantic signals from Twitter, improving covariance estimation and portfolio optimization. Integrating text-derived covariance information into mean-variance optimization produced excellent performance, especially during the COVID-19 crash. Steinert and Altmann [60], meanwhile, used GPT-4 to analyze microblog posts on StockTwits and achieved notable superiority over buy-and-hold strategies in Apple and Tesla, highlighting the potential of LLMs to predict stock-price moves through sentiment analysis. Even so, social-media data also brings special challenges, including enormous volume, colloquial language, selection bias, and misleading or inaccurate messages, all of which complicate accurate measurement of market sentiment [178].
The uncertainty of social-media data distributions is a major issue. Without a strong logic chain, it seems hard to build robust event-driven strategies on top of it.
News is another crucial data source. It resembles social media in its speed and broad coverage, but it is usually more focused on objective events. Unlike the often subjective and personalized nature of social media, news usually comes from more established media institutions, including major newspapers, broadcasters, and dedicated financial publications. The credibility and professionalism of those journalists and writers makes the content more trustworthy, though sometimes at the cost of speed. Growing evidence supports the advantages of ChatGPT-like LLMs over earlier methods, especially in analyzing the sentiment of news headlines. Lopez-Lira and Tang [152] studied ChatGPT’s effectiveness for predicting stock-market returns and showed that it can assign sentiment scores to headlines accurately while outperforming earlier models such as GPT-2 and BERT. Fatouros et al. [153] found that GPT-3.5 improves substantially on FinBERT for foreign-exchange news headlines. Luo and Gong [154] reported strong results using the open-source Llama2-7B model, which outperformed earlier BERT-based methods and traditional LSTM and ELMo approaches. These studies highlight the importance of advanced LLMs for decision-making and quantitative trading.
In the digital era, real-time news has become increasingly common. Distributed through live streams and online platforms, these sources strike a balance between timeliness and accuracy and provide prompt insight into market conditions and public events that may affect financial sentiment [179]. Chen et al. [180] study advanced LLMs such as BERT, RoBERTa, and OPT for sentiment analysis and stock prediction. By capturing complex textual information and providing better contextual understanding, these models significantly outperform traditional methods such as Word2vec and deliver higher accuracy. The study also finds higher Sharpe ratios and better portfolio performance. Crucially, it suggests that because of limits to arbitrage, the incorporation of news into stock prices is delayed, which creates an opportunity for real-time trading strategies to exploit that inefficiency. This underscores the potential of LLMs in real-time financial text mining.
The challenge in using LLMs for real-time news analysis and decisions is training data. One possible route is to build it from past linkages between news and price moves.
Corporate communication covers official statements, press releases, and announcements issued by firms to stakeholders. The sentiment embedded in those communications can strongly shape how stakeholders view a company’s current condition and future prospects. LLMs can process these communications to evaluate sentiment and identify information with potential market impact. For example, Kim et al. [157] show that ChatGPT can significantly simplify and clarify corporate disclosures to investors by shortening them, amplifying the emotional content, and exposing the common problem of “redundancy” in financial reports, that is, excessive, repetitive, or irrelevant information that obscures the insights investors actually need.
Multimodal inputs may add information here, such as vocal tone in speeches.
Analyst reports cover a broad range of data including economic indicators, industry analysis, and consumer behavior, and are highly relevant for financial decisions. Their importance lies in the detailed security analysis and recommendations they provide, helping investors understand market trends and potential opportunities. Analyst ratings such as “buy,” “hold,” and “sell” offer concise assessments of future security performance and are watched closely by investors as signals of market sentiment and strategic guidance [160].
This is a very traditional direction.
Time-Series Forecasting
LLMs can also be used directly for stock prediction, as described in [209]. That work explores the use of LLMs to predict stocks in the Nasdaq 100 and shows that by integrating multiple data sources, LLMs can provide robust forecasts while also improving interpretability. The study highlights the importance of instruction tuning and chain-of-thought reasoning, both of which significantly improve LLM performance in this domain and outperform traditional statistical models. Another route is to integrate LLMs to enhance other neural networks. In [210], Chen et al. introduce a framework that uses ChatGPT to enhance graph neural networks for stock-movement prediction. Their method cleverly extracts evolving network structure from text data and feeds those networks into a GNN for forecasting. Experimental results show that the model consistently outperforms state-of-the-art deep-learning baselines in annualized cumulative return and lower volatility.
LLMs have also drawn attention for their ability to integrate multimodal data analysis, which, as discussed above, is crucial for alternative data. For example, Wimmer and Rekabsaz [211] introduce an innovative model that uses text and visual data to predict market movements. Their research shows that CLIP-based models outperform existing baselines on German stock-index trend prediction. Metrics such as precision, F1 score, and balanced accuracy demonstrate the effectiveness of these multimodal methods. Another notable study is the RiskLabs framework, which combines multiple types of financial data, including text and speech from earnings calls, market-related time-series data, and contextual news [212]. Its multi-stage process first uses LLMs to extract and analyze those inputs, then models time-series data to estimate risk across different horizons. RiskLabs uses multimodal fusion to combine these diverse features for comprehensive multi-task financial risk forecasting. Empirical results show that the framework is effective for predicting volatility and variance in financial markets, illustrating the promise of LLMs in financial risk assessment.
LLMs provide multimodal data-processing capability. They can generate forecasts directly and also complement existing end-to-end models built on price and volume data.
Trends in Large Language Models and Their Applications in Quantitative Investing